Para conhecer a soluçãoQuantRisk™ daModulopara Gestão Quantitativa de Riscos utilizando o Open FAIR™
Modelos matemáticos estão presentes em várias áreas da vida, ajudando a torná-las mais seguras, eficientes e precisas. Através da análise estatística e da teoria da probabilidade, é possível desenvolver modelos para gestão de riscos, por exemplo, para estimar a probabilidade de um evento de segurança cibernética e seus possíveis impactos financeiros.
Nesse contexto, por meio de uma abordagem quantitativa e estruturada, a metodologia doOpen FAIR™(Factor Analysis of Information Risk) tem se destacado como um padrão cada vez mais utilizado para quantificar e gerenciar os riscos em termos financeiros.

Quando comecei a estudar o FAIR, me transportei de volta para as aulas de Estatística do curso de Informática da UFRJ – Universidade Federal do Rio de Janeiro, apresentando o complexo domínio da matemática, com suas fórmulas, técnicas e conceitos.
Padronizada pelo OpenGroup, o Open FAIR™ oferece uma abordagem sistemática para gerenciar riscos, de forma quantitativa, documentada em seus dois principais documentos: Análise de Riscos (O-RA™) e Taxonomia de Riscos (O-RT™), com versões disponíveis em português.
Este artigo se baseia no documento publicado peloOpenGroupem setembro de 2022 (The Mathematics of the Open FAIR™ Methodology), que apresenta uma visão geral de conceitos e técnicas matemáticas, que podem ser usadas para criar modelos para o FAIR.

O documento explica como modelos de probabilidade e estatística podem ser aplicados no Open FAIR™, com ideias e técnicas para quantificar o risco de forma mais precisa e acurada. Enfatiza que é necessário apenas um conjunto reduzido de técnicas para modelagem dos diferentes cenários de risco, premissas para a estimativa de eventos futuros e interpretação dos resultados.
Embora haja flexibilidade no uso dos parâmetros do FAIR,existem também certas regras probabilísticas simples que precisam ser respeitadas, evitando erros comuns e explica como corrigi-los.
Como boa prática, deve-se também manter os modelos o mais simples possível. Quanto mais simples o modelo, menos parâmetros e suposições, menos propensão a erros, mais fácil avaliar se os resultados são confiáveis e atualizar seus valores conforme mudanças nas circunstâncias.
Exemplos de modelos simples em segurança cibernética incluem a avaliação de riscos de ransomware, ataques cibernéticos ou vazamento de dados, considerando apenas algumas variáveis-chave, como a lista de ativos mais relevantes, as principais ameaças e agentes de ameaça, e as perdas mais significativas em termos de impacto financeiro.
Alguns conceitos e exemplos de técnicas apresentados são:
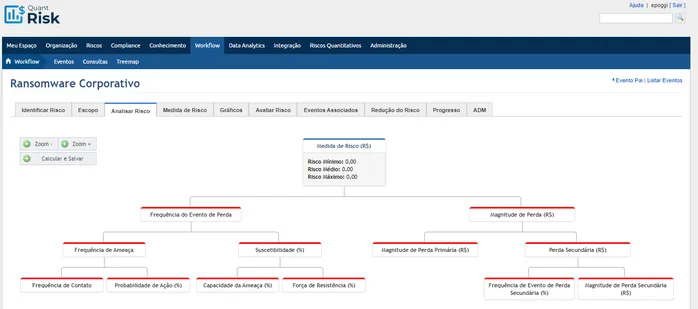
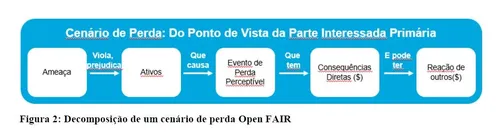
Uma visualização comum dos parâmetros do Open FAIR™ mostra o risco no topo de uma pirâmide, com os fatores do cálculo da Frequência à esquerda, e os da Magnitude à direita. Esta visualização também pode ser lida da esquerda para a direita, em uma sequência temporal, como mostrado na figura:
Frequência: Existem diversas técnicas que podem ser usadas para se calcular a Frequência, dependendo do cenário, como por exemplo distribuições de Bernoulli, Binomial ou Poisson.
Magnitude: Para modelar a Magnitude,o FAIR considera seis formas de perdas primárias ou secundárias: produtividade, resposta, substituição, multas e julgamentos, vantagem competitiva e reputação. Cada perda pode ser descrita por um valor fixo ou uma combinação de distribuições de probabilidade e a perda total pode ser calculada utilizando-se Simulação de Monte Carlo.
Para calcular o valor dos controles e ações de tratamento dos riscos, pode-se partir da redução da perda esperada ao longo de um período, menos os custos de implementação e manutenção. Esta diferença é o benefício monetário dos controles, e oRetorno sobre o Investimento(ROI) é calculado dividindo este benefício pelos custos dos controles.
É importante considerar que toda estimativa é uma previsão incerta, por isso, razoável usar Simulação de Monte Carlo para estimar os valores e ter alguma margem de erro na avaliação.
Para construir um modelo FAIR, existem muitas técnicas que podem ser usadas para estimar seus parâmetros, mas a melhor prática é buscar o máximo de dados possível para basear as estimativas. Dados históricos ou semelhantes podem ser usados, considerando-se a sua qualidade, para garantir que sejam confiáveis e medidos adequadamente. Além disso, dados de terceiros, podem precisar de redimensionamento para refletir a realidade de cada negócio.
No final das contas, qualquer método de estimativa é um modelo que tem suposições associadas, que devem ser documentadas e, se possível, testadas.
Abraços e até a próxima,